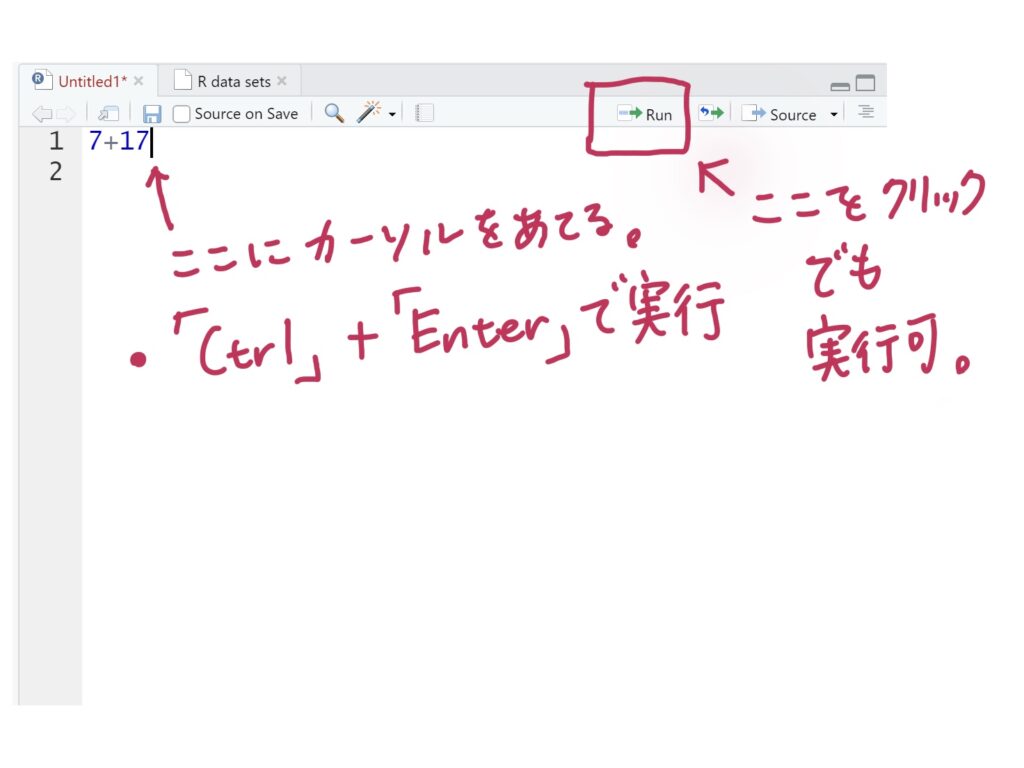
◆データの読み込み
多変量解析で用いるデータを,外部(パソコン上や,インターネット上)からRへ読み込む.今回の演習で扱うデータは,CSV(Comma-Separated Values)と呼ばれるデータ形式のものを利用する.CSVは,Excelやテキストエディタなどのソフトウェアで開くことが出来る.
CSV形式のデータファイルは,read.csv関数で読み込むことが出来る.read.csvのあとの括弧()の中にある「file」や「header = TRUE」のことを引数(ひきすう)という.引数は複数指定することができ,左から「第一引数」「第二引数」という.第一引数は,読み込みたいファイルが置いてあるフォルダのパスとファイル名をつなげて指定する.
read.csv(file, header = TRUE, sep = ",",...)
◆コロナウイルス感染者データの入手と読み込み
都道府県別新型コロナウイルス感染者数マップ URL では,発表された症例一覧のCSVファイルが入手できる.
コロナウイルス感染者データの読み込みと表示
このCSVデータにはいくつかの欠損値などがあり扱いにくい.そこで,今回の演習用に,加工したデータを以下のURLに置いた.
https://fnakai.web.nitech.ac.jp/data/COVID-19_modified.csv
このデータをread.csv関数を使って読み込み,読み込んだファイルを「COVID-19」というオブジェクトに代入(付値)せよ.URL指定による方法でも,ローカルフォルダに保存してから読み込む方法でも,どちらでも良い.
第一引数には,ファイルのパス/ファイル名を” “(ダブルクオーテーション)でくくって指定する.また,第二引数には,header= TRUEを指定する.これは「1行目は列名を意味しますよ」ということを示すものである.第3引数にはsep=”,”を指定する.sepという引数は,読み込むファイルが ,(カンマ)で区切られていることを示すものである.
1.オンライン上のデータを読み込む方法(URLを指定してアクセス)
※今回の演習ではRstudio Cloudを使う都合上,こちらの方法で読み込む
第一引数には,以下のURLを” “(ダブルクオーテーション)でくくって指定する.
https://fnakai.web.nitech.ac.jp/data/COVID-19_modified.csv
2.ローカルフォルダのデータを読み込む方法(フォルダのパスを指定してアクセス)
データをダウンロードし,EIP2020に保存する.そして,そのデータをread.csv関数を使って読み込む.
第一引数には,(1)フォルダのフルパス”C:/Users/Fuko Nakai/Desktop/EIP2020/NagoyaCity_population_en.csv “を指定する方法,(2)ファイル名”NagoyaCity_population_en.csv “だけ指定する方法がある.(2)は,CWDを省略した表記である.今回はCWDがEIP2020に指定されているため省略可能であるが,CWDとは異なるパスのファイルを読み込む場合には,フルパスを指定する.
以下は,一度ローカルフォルダに保存してから読み込むケースである.colClassesという引数を用いて各列のデータ型を指定する.
COVID19 <- read.csv("COVID-19_modified.csv",
sep=",",
colClasses = c("integer","integer","character","character","character","Date"))
オブジェクト名を入力し,実行すると,読み込んだデータの中身を見ることができる.「COVID19」と入力し,中身を確認せよ.また,以下の表に示す列が現れることを確認せよ.
| データの列名 | 内容 |
| ID | 本CSV内におけるデータの通し番号 |
| Age | 公表された年代。10歳刻み。 10歳未満の場合「0-10」と記載。実際の年齢が公表された場合にも年代に丸めて記載。不明もしくは非公表の場合には「不明」と記載。 |
| Hospital Pref | 受診都道府県 |
| Residential Pref | 居住都道府県(居住地) |
| Gender | 公表された性別、男性、女性。 不明もしくは非公表の場合には「不明」と記載。 |
| Confirmation Date | PCR検査における陽性が判明した日。 日付は日本時間(JST)。自治体の公表日(報道発表資料公開日)や、報道された日付ではない。 |
演習用データ COVID-19_modified.csv の定義(引用:新型コロナウイルス感染者数マップ)各列のデータの表示
読み込んだデータの型がdata.frameという形式の場合,「オブジェクト名$列名」と指定することで,各列のデータのみを表示できる.今回は,既にdata.frame型になっている.たとえば,居住都道府県(居住地)のみのデータを表示したければ,以下のように入力すればよい.
◆データの要約
膨大なデータの概観を得るためには,データの特徴を少数の値に要約する(まとめる)ことがもとめられる.ここでは,table関数,summary関数を用いたデータの要約をおこなう.
問1 table関数を用いた都道府県別感染者数の集計
COVID-19は,1つのレコードに感染者1名分のデータが入っている.これを,各列ごとに集計してみよう.まずは,下記のコードを入力してみてほしい.どのような結果が出てきただろうか?
table(COVID19$Residential.Pref)
?table
実行結果を踏まえて,以下の1,2に答えよ.
- Age,Hospital Pref,Residential Pref,Genderの4つの列について,table関数による集計を実行し,そのコードを示せ.
- 「?table」は,table関数がどのような関数を表示するコマンドである.これを参考に,table関数がどのような関数か,説明せよ.
問2 summary関数を用いた要約
下記のコードを実行せよ.
列ごとに,「Min.」「1st Qu.」「Median」「Mean」「3rd Qu.」「Max.」「NA’s」という項目が表示される.これは,上から順に「最小値」「第 1 四分位点」「中央値」「平均」「第 3 四分位点」「最大値」「NAの数」を意味する.「NA」は,データの欠損を意味する.また,数値データ以外の列は,「Length」「Class」「Mode」となっており,それぞれ「データの数(行数),データ型,データ型」を意味する.
summary関数の実行結果を踏まえて,以下の1,2に答えよ.
- 今回演習で扱うCOVID19データには何人分のデータが入っているか.
- Ageの列の平均値,最小値,最大値を求めよ.
- 今回Ageの列において,欠損しているデータはいくつあるか.
◆量的データの可視化
膨大なデータの概観を把握するもう一つの手法は「可視化」である.量的データの可視化法として最も代表的なのがヒストグラム(度数分布)である.度数分布はhist関数を用いて表示することができる.
問3 hist関数を用いた年代データの可視化
年代に関する度数分布を表示する下記のコードを実行せよ.
hist(x = COVID19$Age,
xlab = "XXX",
ylab = "XXX",
main = "XXX",
col = "red",
border = "gray",
breaks=seq(0,100,by=10))
各引数の意味は以下の通りである.
| x | ヒストグラムを描く変数(ベクトル形式) |
| breaks | ヒストグラムの横軸の範囲と分割の幅(ベクトル形式) |
| xlab, | 横軸の名称(文字列) |
| ylab | 縦軸の名称(文字列) |
| main | ヒストグラム上のタイトル(文字列) |
| col | ヒストグラムの棒の色を指定(文字列または数値) |
| border | 棒の枠の色を指定(文字列または数値) |
| breaks | ベクトル形式で,階級分けの下端値から上端値の値を指定する.例えばbreaks=seq(0,100,by=10)は「0歳代から100歳代までの年齢を10歳刻みのヒストグラムに分けよ」という意味である. |
各引数の意味実行結果を踏まえて,以下の問いに答えよ.
- 縦軸に「頻度」,横軸に「年代」,タイトルに「年代のヒストグラム」と指定し,棒とその枠の色を「black」としたヒストグラムを描け.また,グラフは,形式を「PNG」にして,EIP2020フォルダに保存し,レポートに貼りつけること(図番号とキャプションもつけること).
- 一番感染者数が多い年代と,少ない年代を答えよ.また,描いたヒストグラムからわかることを説明せよ.
問4 hist関数を用いた陽性判明日データの可視化
陽性が判明した日に関する度数分布を表示する下記のコードを実行せよ.
hist(x = COVID19$Confirmation.Date,
breaks = length(unique(COVID19$Confirmation.Date)),
xlab = "XXX",
ylab = "XXX",
main = "XXX",
col = "gray",
freq = TRUE)
上記を実行した結果、以下のようなエラー文「’x’ must be numeric(オブジェクト’x’は実数型でなければいけない)」が出る場合がある。これは、COVID19$Confirmation.Dateというオブジェクトが、単なる文字列として扱われているためである。この場合、
> hist(x = COVID19$Confirmation.Date,
+ breaks = length(unique(COVID19$Confirmation.Date)),
+ xlab = "XXX",
+ ylab = "XXX",
+ main = "XXX",
+ col = "gray",
+ freq = TRUE)
Error in hist.default(x = COVID19$Confirmation.Date, breaks = length(unique(COVID19$Confirmation.Date)), :
'x' must be numeric
hist()関数を実行する「前」に以下のコードを実行する。as.Date()は、()内の日付に関するオブジェクトをcharacter型からDate型へ変換する関数である。変換した後の結果を、オブジェクトCOVID19$Confirmation.Dateに改めて代入する。
COVID19$Confirmation.Date <- as.Date(COVID19$Confirmation.Date)
hist関数の実行結果を踏まえて,以下の問いに答えよ.
- 縦軸,横軸,タイトルに適当(データを的確に表すよう)な文字列が入るよう,引数を指定したヒストグラムを描け.また,グラフは,形式を「PNG」にして,EIP2020フォルダに保存し,レポートに貼りつけること(図番号とキャプションもつけること).
- summary関数を用いて,いつからいつまでの期間のデータが収録されているかを示せ.
- 陽性が判明した日について,ヒストグラムからわかることを3つ以上挙げよ.
◆質的データの可視化
質的データを可視化するには,各カテゴリに属する割合を図示するのが良い.ここでは円グラフを扱う.円グラフは,pie関数を用いて表示することができる.
問5 pie関数を用いた性別データの可視化
性別に関する度数分布を表示する下記のコードを実行せよ.
x <- table(COVID19$Gender)
pie(x, clockwise = TRUE)
第一引数には,各カテゴリの個体数をベクトルで指定する必要がある.第二引数のclockwiseには,カテゴリの順序を反時計回りに配置するかをTRUE,FALSEで指定する.
実行結果を踏まえて,以下の問いに答えよ.
- グラフを描き,形式を「PNG」にして,EIP2020フォルダに保存し,レポートに貼りつけること(図番号とキャプションもつけること).
- 今回は「x <- table(COVID19$Gender)」を実行してから,「pie(x, clockwise = TRUE)」を実行している.この二行がどのような操作を意味するのか,なぜ一行目が必要であるのかを説明せよ.
- 円グラフからわかることを説明せよ.
◆データの抽出
ここまでは,全国のデータを扱ってきたが,愛知県のデータだけを取り出して,そのデータの特性を見る.
下記のコードを入力してみてほしい.急にややこしいのが出てきた,と思うかもしれないが,一つ一つ丁寧に見てみよう.
AichiCOVID19 <- COVID19[which(COVID19$Residential.Pref=="Aichi"),]
まず,以下のコードを実行してみてほしい.FALSEやTRUEという文字列が現れる.これは,COVID19$Residential.Prefの値が”Aichi”であればTRUE,そうでなければ”FALSE”を返している.
COVID19$Residential.Pref=="Aichi"
次に,以下のコードを実行してみる.which関数である.これは,which( )の中の論理式を満たす行の番号を抽出する関数である.つまりCOVID19$Residential.Prefの値が”Aichi”である行の番号一覧が返されていることになる.
which(COVID19$Residential.Pref=="Aichi")
最後に,以下のコードを実行してみる.以下のようにオブジェクト名[ ]と表記しているのは,[ ]の数字を使ってオブジェクトの何番目のデータを取り出すかを指定するものである.今回は行列データを扱っているのでオブジェクト名[i,j]でi行j列のデータを指定することが出来る.iもjも,ベクトルで指定することが出来る.which関数の結果はベクトル形式になっているから,そのベクトルの数値に該当する行のデータを返すことになる.
COVID19[which(COVID19$Residential.Pref=="Aichi"),]
問6 データの抽出
全国のデータから岐阜県(”Gifu”)のデータだけを取り出し,オブジェクト名「GifuCOVID19」に付値せよ.また,そのコードを示せ.
◆発展課題(+10点)
以下の問題は,できる範囲で取り組んでください.
- 好きな都道府県(愛知,岐阜,あるいはそれ以外)を選び,hist関数を用いた年代データと陽性判明日データ,pie関数を用いた性別データの可視化をおこない,保存し,レポートに張り付けよ.
- 結果について,全国を対象に分析した問1~問5の結果と比較し,考察しなさい.